- Published on
Adding cool search to my blog. Part 1
- Author

- Illia Vasylevskyi
My blog search system was really simple using two-sided LIKE on title, so let's create cool site search using ML and Python.
You can find code in repository github.com/ineersa/blog-search
Information retrieval is known for a long time now, and with the rise of LLM's and RAG systems it seems to get a wave of popularity.
To understand what RAG is, we should understand how we would've search information without it, let's explore some methods:
- search by two-sided LIKE is quite bad, first of all it's slow, second - we cannot distinguish words from parts of words.
- search by words, we can split our texts into words, search by them, or use fulltext search, but this will not work for example with things like
I know,They knew - we can use word lemma's for example, instead of words, which will make our search better, but we still will have problems with stopwords for example, which will not allow us to search for a whole phrase instead of words
- to determine if 2 phrases are similar, we can check if keywords from both phrases are equal, for this we can use TF-IDF scores, this approach would work, and surprisingly good - but it also has some issues, like it has no normalization (we can't tell how much 1 phrase is similar to another), scores can grow, it has no document length normalization
- well, since tf-idf has all those problems BM25 algo was created, which improves TF calculation via adding decay function and adds document length normalization, but it still lacks normalization part. This approach is excellent to search by keywords, and widely used in tools like ElasticSearch, also it scales well and computationally efficient
- problem with this as it doesn't know about semantics, so for example if you are looking information about royalties and type
kingyou want to see information aboutqueenalso, and keyword search is unable to help with this.
So to implement semantic search we have different options:
- we can implement search based on words semantic meaning, using
Word2Vecfor example orGloveembeddings, but this will miss correlation between words inside phrase - we can convert our phrase into vector, using
Doc2Vecor sentence embeddings usingBert,Transformersor LLM's
Two similar phrases in vector space will point into same direction, so less the angle between them, the more similar they are. This is actually a definition of cosine similarity which is widely used to compare 2 vectors.
So we will implement vector search for retrieval of our blog posts.
Let's see on project architecture which will be close to modern RAG systems:
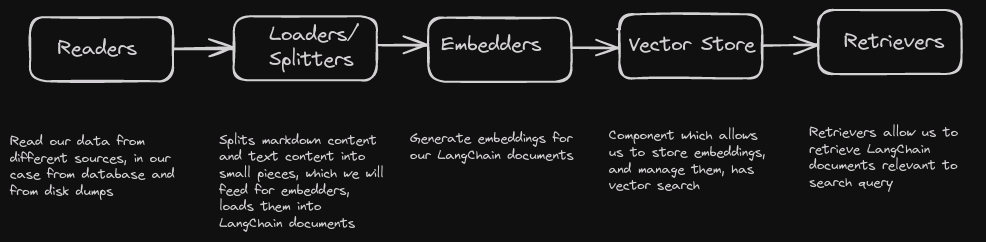
To get full RAG system, you should add here Generator part, but for our search system it's not needed.
For implementation, I've used:
FastAPIto serve search requestsChromaDBas vector storeLangChainused some components to not invent the wheelSentenceTransformersexcellent library to generate embeddings for semantic similarity
Check out technical aspects on github.com/ineersa/blog-search