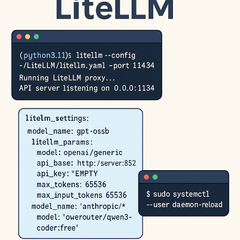
Since we built `llama.cpp` from source, now we can run our models.
Different models have different settings, so you need to check model cards always before run.
AI models are getting smaller and now more broadly available to run on consumer grade hardware. You can run Ollama or LMStudio for easy models testing and integrations, for example, you can connect it to Jetbrains AI Assistant.